Introductory Programming in Python: Lesson 31
Advanced Data Structures: Trees
Trees in The Wild
If we look at a tree in nature, we notice a repeating pattern. The trunk of the tree splits off into smaller versions of itself (which we call branches). The trunk is a straightish piece of wood, only different from a branch by virtue of its direct connection to a root system, from which multiple smaller straightish pieces of wood, called branches, extend. From each branch, a number of smaller branches may extend, and so on and so forth, until branch is eventually small enough to be called a twig. We see that a twig has no branches extending off it, and also ends in a leaf. We see the repeating pattern is that trunks are the same as branches which are the same as twigs. The only difference is the number of branches coming off them. And thus we have defined the structure of a tree recursively; defined it in smaller terms of itself.
Trees as a Recursive Data Structure
In programming we find many structures imitate that of a tree, such that a particular piece of data may contain any number of pieces of data of the same structure as itself. We call something having these properties a tree, after the structure in nature that it mimics. Trees in programming consist of nodes and edges. Any node in a tree may contain any number of subtrees, which are edges to another node. For example we might represent familial relations with a tree, as in
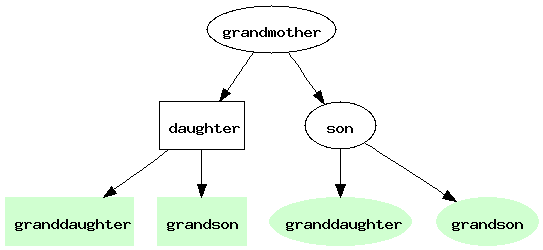
The node 'grandmother' is the root of the tree. However, the node 'daughter' is also the root of the subtree whose nodes are rectangular. The green shaded nodes are known as leaf nodes because they have no subtrees.
A Python Class to Store Trees
Let's create a python class to represent a tree. We need some way to store data in a node, and some way to indicate any child nodes, or subtrees.
class node(object):
def __init__(self, value, children = None):
self.value = value
#remember we can't use a list (mutable object) as a default parameter
if self.children is not None:
self.children = children
else:
self.children = []
Whoa! That seems way too easy... but believe it or not, it does the job. Let's use our new class to store our family tree...
tree = node("grandmother", [
node("daughter", [
node("granddaughter"),
node("grandson")]),
node("son", [
node("granddaughter"),
node("grandson")])
]);
Traversing a Tree
We often find we wish to do something to every node in a tree. We may wish to display the data that the nodes contain, to sum the values of the nodes in the tree, etc ... We need a method to traverse every node in a tree, such that each node is visited exactly once. Well, we have a recursive data structure, so we should look at using a recursive function to traverse it.
Of course printing a node object isn't very helpful to us at the moment, so let's redefine the '__repr__' method to do something more useful...
class node(object):
def __init__(self, value, children = None):
self.value = value
if self.children is not None:
self.children = children
else:
self.children = []
def __repr__(self, level=0):
ret = "\t"*level+repr(self.value)+"\n"
for child in self.children:
ret += child.__repr__(level+1)
return ret
Now when we print tree we get
'grandmother'
'daughter'
'granddaughter'
'grandson'
'son'
'granddaughter'
'grandson'
Here we have used a recursive function for '__repr__'. Our simplest case is a leaf node, with no children. We simply return the value of the node. In the more complex case, we return the value of the node concatenated with the representation of all it's children.
There are of course two ways to go about traversing a generic tree. We can handle each node we encounter before we handle its subtrees, known as a pre-order traversal, or we can handle the subtrees first, and then only the nodes themselves, known as a post-order traversal. Computer scientists are nothing if not original with their naming schemes. Our choice should depend on why we are traversing the tree. For the purposes of display, pre-order is normally preferred. However for the purposes of producing output in a different order, post-order may be more useful, as we'll see when we deal with binary trees. There are two more methods of tree traversal, namely in-order which is primarily only useful in binary trees. The other, more generally applicable traversal method, is known as a level-order traversal where we visit every all nodes at a particular level, i.e. distance from the root of the whole tree, before progressing to any node of a lower, i.e. further from the root, level.
Pre, post, and in-order traversals are broadly classified as depth-first traversals/searches, because they dive deeper into the structure before moving across to the next child. Conversely, the level-order traversal is a breadth-first traversal/search because it broadens it's search across a level before diving deeper down.
Binary Trees
A binary tree is a special case of a generic tree with additional properties.
- Each node may have a maximum of two subtrees, the left subtree and the right subtree.
- All values in the left subtree of a node are less than the value of the node itself.
- All values in the right subtree of a node are more than the value of the node itself.
- The same value cannot appear more than once in the tree.
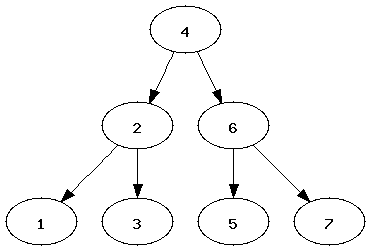
Binary Tree Traversal
When dealing with binary trees, the order of traversal makes a huge difference, because the binary tree can be considered 'ordered' or 'sorted'. In-order traversals handle the left sub-tree first, then the node, then the right subtree, so starting at the root of our example (4), we first progress to the left subtree (2), from whence we visit the left subtree again (1), we process 1. Coming back to 2, we process the node, i.e. 2. the we process the right subtree (3), which has no children. Now we bounce back from 2 to 4, process 4, then move to 4's right subtree (6). We then process 6's left subtree (5), then 6 itself, then 7. So we see that an in-order traversal of a binary tree gives us the values in sorted order.
Pre-order and post-order traversals can be used to extract different
orders from the tree, for different purposes. Pre-order traversals are
best used to display the tree in a nicely formatted way, to make a copy
of the tree by inserting each visited node. They can also be used to
evaluate expression trees. Let's take our favorite expression
(4*(2+3)) and put it in a binary tree, well almost, it
violates conditions 2, 3 and 4 ... this particular from of tree is
known as either an expression tree or an
abstract syntax tree (AST).
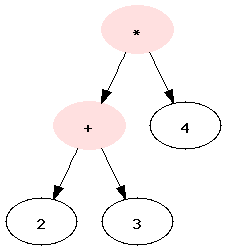
Now let's write a class to handle an expression tree. We notice that numbers are always leaves, and that that operators always have both a left and a right sub-tree. The expression isn't valid if these conditions are not true, so our evaluate method makes those assumptions and doesn't check for errors. So now we want to do a pre-order traversal of the tree, at each node checking if it's an operator, and if so, applying that operator to the evaluation of the left tree, and the right tree as operands.
class exprnode(object):
def __init__(self, value = None, left = None, right = None):
self.value = value
self.left = left
self.right = right
def evaluate(self):
if self.value == '+':
return self.left.evaluate() + self.right.evaluate()
elif self.value == '-':
return self.left.evaluate() - self.right.evaluate()
elif self.value == '*':
return self.left.evaluate() * self.right.evaluate()
elif self.value == '/':
return self.left.evaluate() / self.right.evaluate()
else:
return self.value
my_expr = exprnode('*',
exprnode('+',
exprnode(2),
exprnode(3)),
exprnode(4))
my_expr.evaluate()
Finding an Item in a Binary Tree
Since no two nodes in a binary tree can have the same value, and we know the order in which the nodes are arranged, we can find whether an item exists in a binary tree very easily, and very very quickly. If we are checking whether some value 'x' is in the tree, we check against the root of the tree. If the root is not 'x', then we know x must be in the left subtree if 'x' is less then the root, otherwise in the right subtree, so we return the search in that subtree. Once again, a quick binary tree class, which we will expand as we continue this topic.
class binarynode(object):
def __init__(self, value, left = None, right = None):
self.value = value
self.left = left
self.right = right
def search(self, value): #returns True if value is in the tree
if self.value == value:
return True
else:
if value < self.value:
if self.left != None:
return self.left.search(value)
else:
return False
else:
if self.right != None:
return self.right.search(value)
else:
return False
Inserting an Item
If we want to insert an item into a binary tree, we simply check whether there is a subtree to insert it into. If so, we check whether it should go to the left or to the right, and recursively call the insert function on the subtree. If there is no subtree in the appropriate direction, then we simply create a new subtree in the correct direction with it's root as our item, and no sub children. The only trick that we have to check for, is that we don't find the item already in the tree. Here's some code, adding a method to the binarynode class...
def insert(self, item):
if self.value == item:
return #we do nothing because the item is already here
else:
if item < self.value:
if self.left != None:
self.left.insert(item)
else:
self.left = binarynode(item)
else:
if self.right != None:
self.right.insert(item)
else:
self.right = binarynode(item)
Let's look at insertion using a few diagrams. We wish to insert the value 3 into a binary tree containing 1,2,4,5,6, and 7. The red node is the one to be inserted, the blue node is the one being processed during the particular step.
Removing an Item
If we wish to remove an item from a tree, we realise very quickly, that the situation is more complex than an insertion. Removing an item that happens to be a leaf node is trivial. Suppose we have a method of a binarynode that returns None if the node's value is the same as the one to delete, otherwise it returns itself. This works ideally in the case of a single node tree. We simply assign the tree to the result of the deletion method.
def delete(self, value):
if value == self.value:
return None
else:
if value < self.value and self.left != None:
self.left = self.left.delete(value)
if value > self.value and self.right != None:
self.right = self.right.delete(value)
return self
But this obviously won't work for an internal node (i.e. not a leaf node), as we would remove it and all its children from the tree. In this case we must somehow rearrange the tree to adhere to the four conditions of binary trees. Conditions two and three are the important ones here. We need to replace the value we are deleting with a value that is greater then every value in the left subtree and less than every value in the right subtree. We also can't add a arbitrary value. Which means we have to find a suitable value, and it's pretty obvious which one it's going to be. Well actually we have two choices, a value from the left or a value from the right. We;ll prefer the left, and only choose from the right if there is no left. We now want to delete the highest value from the left subtree, and make the value of the deleted node equal to that value, and to delete the highest value from the left. Similarly, we want the lowest value from the right subtree if we are forced to go that way. Pretty picture time... We want to delete the value in red from the tree, an each given step we compare the value in red to the value in blue, and make a decision to go left or right. When red equals blue, we follow green to find the highest value in the left sub tree, and delete it (which is easy because it's guaranteed to be a leaf node), and replace the blue value with the green value.
As we can see this method preserves the integrity of the tree, i.e. all the rules are still in force. Try thinking through the deletion process for '4' in the example tree, and we see it work's for the root node. Now let's write some code...
def highest(self):
if self.right != None:
return self.right.highest()
else:
return self.value
def lowest(self):
if self.left != None:
return self.left.lowest()
else:
return self.value
def delete(self, value):
if value == self.value:
if self.left != None:
self.value = self.left.highest()
self.left.delete(self.value)
elif self.right != None:
self.value = self.right.lowest()
self.right.delete(self.value)
else:
return None
else:
if value < self.value and self.left != None:
self.left = self.left.delete(value)
if value > self.value and self.right != None:
self.right = self.right.delete(value)
return self
As a mental exercise, why do we just have to visit the right or left subtrees to find the highest or lowest values in a tree respectively.
Balancing a Binary Tree
Depending on the order in which values are inserted or deleted from a binary tree, we might unbalance the tree. For example, adding every value in order will just give us a long chain of right subtrees, which looks very much like a list. In this case we want to balance the tree. We define a tree to be unbalanced when the depth of it's left subtree is different from the depth of it's right subtree by more than one. In the case where a tree is unbalanced, we rotate right if the depth of the right subtree is less, otherwise left. We keep rotating until the tree is balanced, then we balance the left subtree, then we balance the right subtree.